2025年行将结束,具身智能一定是今年的科技年度热词。
但与热度并存的,是具身领域从未停止的争论:Demo外机器人的真实干活水平如何?除了表演,它们还能做到什么?具身模型的进展如何?数据问题如何解决?…
站在2025年的尾巴上审视,这些问题的答案不算明朗。
在这个时点,清华大学姚班助理教授、伯克利归国四子之一的许华哲,也在社交媒体上发表了他对具身领域的2025年回望。
*许华哲社媒
在这篇名为《具身智能,2025回望》的文章中,许华哲认为,当下具身领域或许存在三个“不协调”:
中国具身公司花更多力气搞量产、美国公司展示AI技术上限。
在美国,Gen0 的精细操作,Sunday 的长程任务能力,pi 0.6 的持续工作能力让人震感,中国则强调量产。量产和商业化固然重要,但机器人需要AI能力来领跑,如果由此引发“技术落后”,得不偿失。
对很多场景来说,目前没有自动化的事情,往往要么单价不高,要么重复度不高。
因此,具身智能相比于传统的工业机器人更像是大模型。就像大模型不应该花时间在“情感理解”,“文章摘要”这样的任务上一样,具身智能不应该做这些简单地任务,而应该去挑战“强操作”、“高泛化”的事情。
足够好的具身智能和世界模型不可能从已有的数据中训练出来,机器人和模型需要“螺旋上升”,边用边训。
以下是许华哲发布在个人社交媒体上的全文。
具身智能:2025回望
北京下雪了。
我在搜狐大厦星巴克刚送走朋友,目送他一段。我当然不是爱上了他,而是想看看他在刚落雪又融化的地面上如何保持平衡。我想结论很简单:不如 G1 机器人,但好在他很聪明。
回想起几年前,我们还在讨论机器人什么时候能全地形走路,后来发现这个话题变成了“跑酷”、“跳舞”、“篮球”。这个变化速率让我知道这个事儿已经成了,如果明年可以攀岩我并不吃惊。
但这极快的变化速率又显得格外不协调,因为我没在任何地方看到人形机器人真正服务人类。快递分拣平均速率是1800件每小时,汽车工厂要万分之一甚至十万分之一的失误率。达成的那一天似乎一直在一个不远不近的地方招手——隔三差五有人宣称任务已经解决,但和跳舞的同行不同,我们只能在视频里见到它。
就像前面说的速率上的不协调,回望2025的具身智能,我发现了好几个这样不协调的相互映照的“对子”。当然我对它们也有个人的主观臆断,所以也请读者担待冒失的地方。
一. 两个世界的机器人梦
从22年、23年同步出发,我们和大洋彼岸几乎同步启航了具身智能的事业。但是到了2025年,我们看到了一个比较明显的分野,中国的公司花更多的力气搞量产、美国公司则展示AI技术上限。
我看到 Generalist 的 Gen0 精细的操作,看到 Sunday 的长程任务能力,看到 pi 0.6 的持续工作能力,内心是有焦虑的。我有一个不好的直觉,我们要评估我们的技术是不是落后,但我想这里,我有责任,@李弘扬 @赵行 @王鹤 @高阳 @庞江淼 @穆尧 @周博宇 @陈源培 @… 也都有责任。量产重不重要,非常重要,但是机器人不是汽车,需要AI能力来领跑。
我觉得我们要适应一件事,就是时代变了。在过往的技术上,我们采用跟随策略;在大模型上我们已经产生了 DeepSeek 这样的原始创新;在具身智能上,我们应该有信心也有概率,最大的那件事儿发生在中国。
我之前在破乎中也有讨论过:“简单说你用修长城的场,不管给多少人、多少机器、多少钱该干不出来还是干不出来,该撵不上就是撵不上”。我理解努力做确定性有收益的事情的那种爽感:我努力、我成长、我收获。但是我想我们真正缺乏的还是:我努力、我失败了99次、但我吸取教训并且期待第100次也许会成功。在一些人“成功地”蒸馏别人的模型时,另一些人在“失败地”研制新的算法。
我认为商业化很重要,也深知量产的严肃性,我只是怕我们错过了最大的那个西瓜。
二. 落地简单场景还是挑战困难场景
这阵子也有看过一些场景,各种各样的工厂。我有一个稍有一点悲观的暂时性结论:高价值高重复的场景,总会出现一个深圳或者无锡的聪明人,造出一套自动化设备解决90%的问题。这个结论的反面是——目前没有自动化的事情,往往要么单价不高,要么重复度不高。因此,我反而觉得具身智能相比于传统的工业机器人更像是大模型。
让我们沿着这一类比去想,就像大模型不应该花时间在“情感理解”,“文章摘要”这样的任务上一样,具身智能就不应该做这些简单地任务,而是应该去挑战“强操作”、“高泛化”的事情。这样我们也更能期待一个高质量的模型,通用地解决许多事情。
当然我们不能否定现有落地的价值,因为很多向具体场景的落地,无论未来的智能模型有多强,都还是需要比较高的迁移成本的,这个路早趟过去也是好的。
三. “预训练” 配合 “先验学习”
具身智能的数据瓶颈天然存在,仿真数据不足、真机数据的缺乏,会逐渐解决但也会持续存在。因此,具身智能恐怕不能先穷尽预训练数据,再走向模型探索,而是需要螺旋上升式地进行探索。
未来我们可能会看到,一个预训练好的模型,用强化学习在一些任务上变得拥有超越人类的能力;而这个模型可能又会在未来更多的数据上——包括增采的和真机探索的——训练得更好。
同样的逻辑,也适用于世界模型,我从不相信我们能够从人类采集好的数据里面训练出一个足够好的世界模型,相反,我们需要机器人真正地自主与世界交互,才能找到真正属于自己的世界模型。我还一直有一个很感兴趣的话题,用一套强化学习目标函数来完成预训练和后训练,但这是来年的事情了。
所有的成长,都是挣扎着向上。
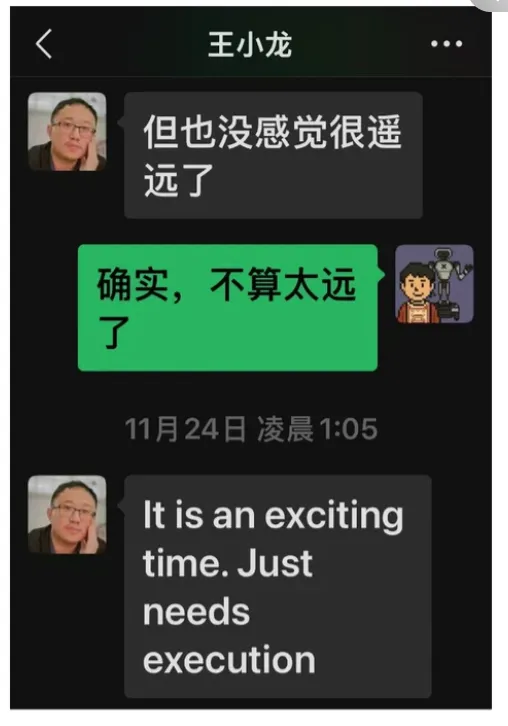
具身智能的2025年,没有一步登天,但是确实越来越强烈地感受到一种未来在召唤。突然想起了前阵子和小龙的一次闲聊。“但也没感觉很遥远了” “确实,不算太远了” “It’s an exciting time. Just needs execution.” 是我们对话的结束。
最后想送给所有梦想着让机器人帮助所有人的朋友,一句《马大帅》里的话:“让我们抓紧时间慢慢等吧”。